Project Details
- 開發者 : 李韋杰
- 主要目的 : 用視覺化找出更多資訊
- 使用工具 : E-charts / JS / ngraph
- 完成時間 : –
- 技能需求 : HTML / Javascript / CSS
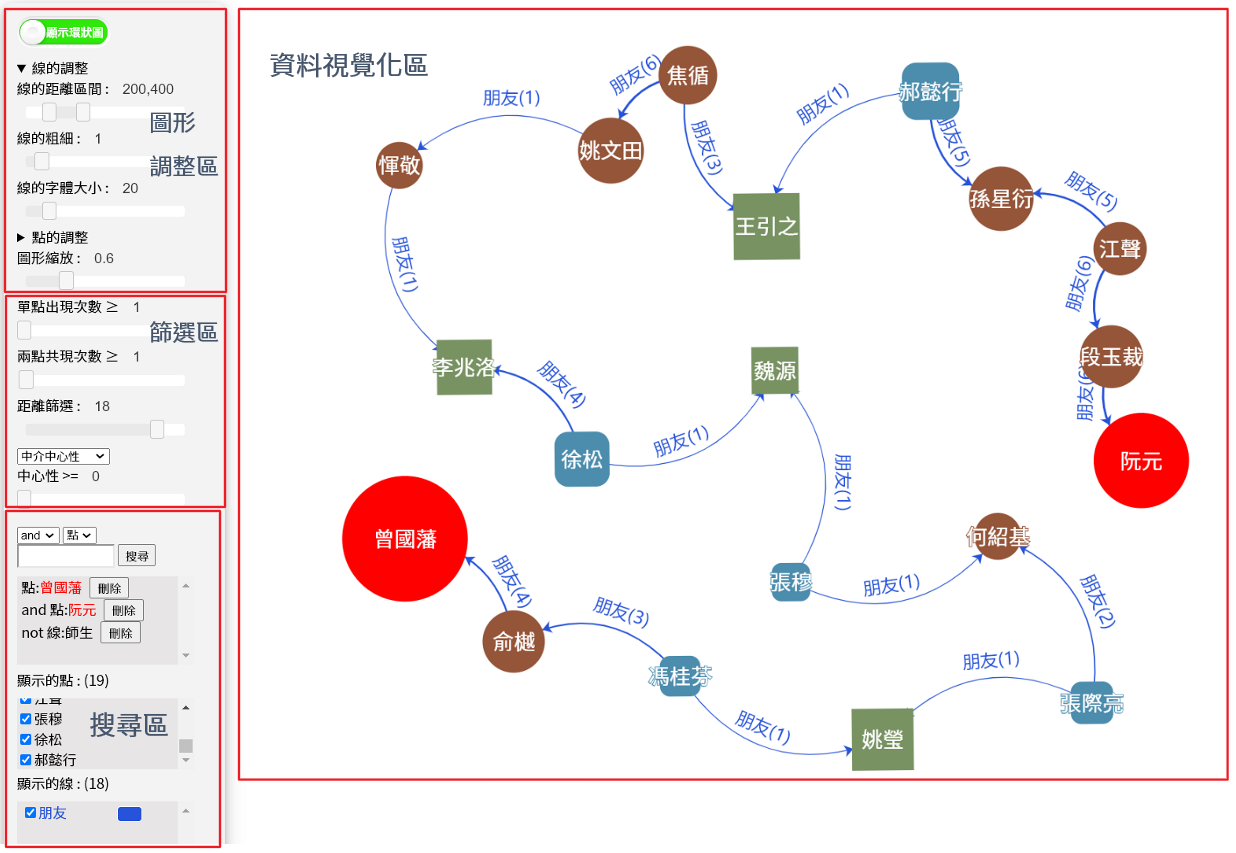
圖 2 軟體畫面
本軟體目的
此軟體的主要功能是協助於中研院數位人文研究平台研究的研究者了解文本中制定的物間之間的關係,並與物件定義資料從視覺化中發現一些細微的關係。但通常書中的資料繁多,因此需要有強大的搜尋功能和篩選功能。而我就在上學期加入了邏輯搜尋功能與多節點間的關係搜尋和節點列表。
功能介紹
資料視覺化區
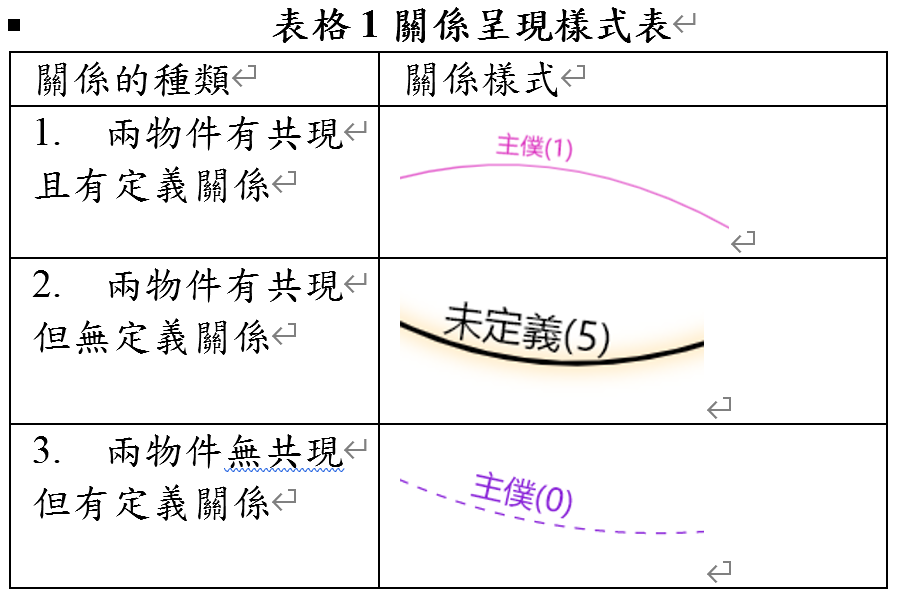
在資料視覺化區中,會以圖形呈現社會網絡分析的資料,我們以節點表示社會網絡分析中的物件、線段表示關係、線段上的文字代表關係的定義、線段上的數字則是共現次數。
我們有兩種圖表可以顯示,一個是環形圖(circular layout)如圖 3所示,特色是會將節點等距排列成環形,在規模小時物件不會重疊及有規則的呈現物件規模與密集程度,另一個是力布局圖(force layout)如圖 4所示,排列方式是計算引力與斥力來算出他們的位置,因此能充分展現整體結構及物件所屬群體。
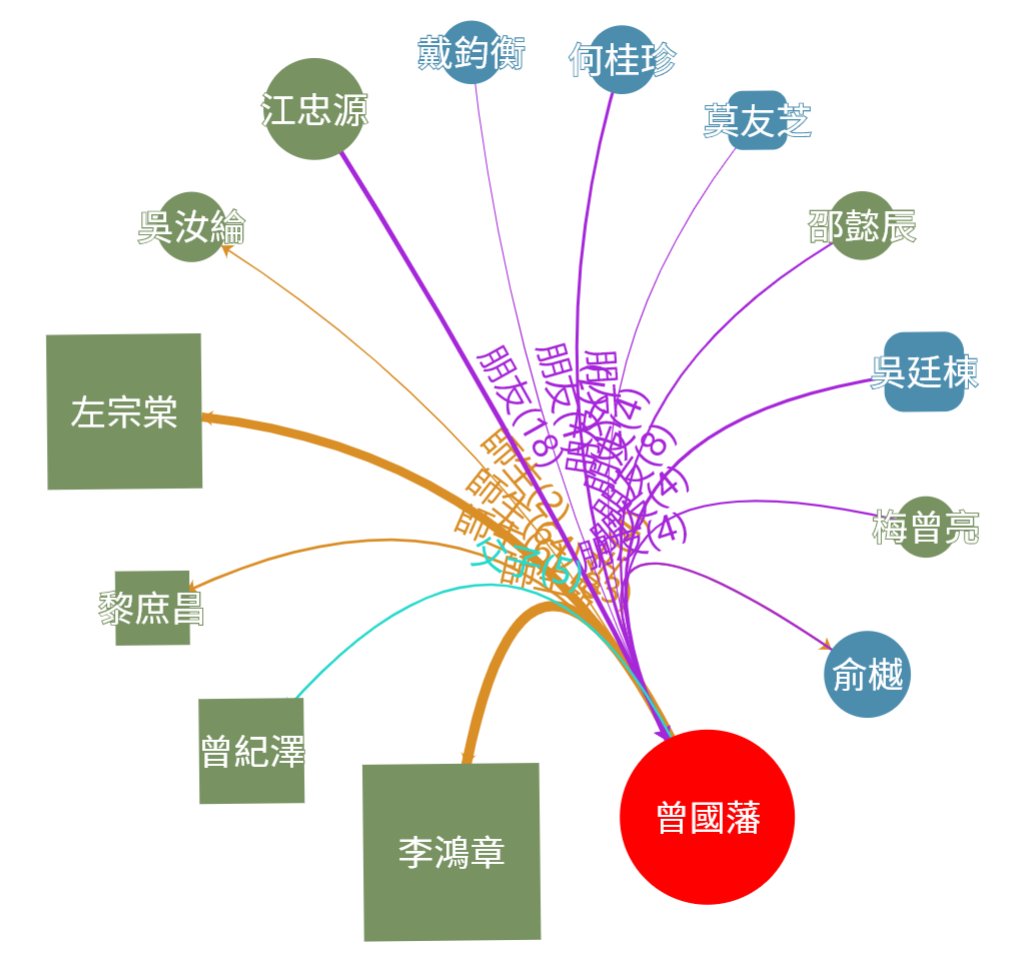
圖 3 環形圖
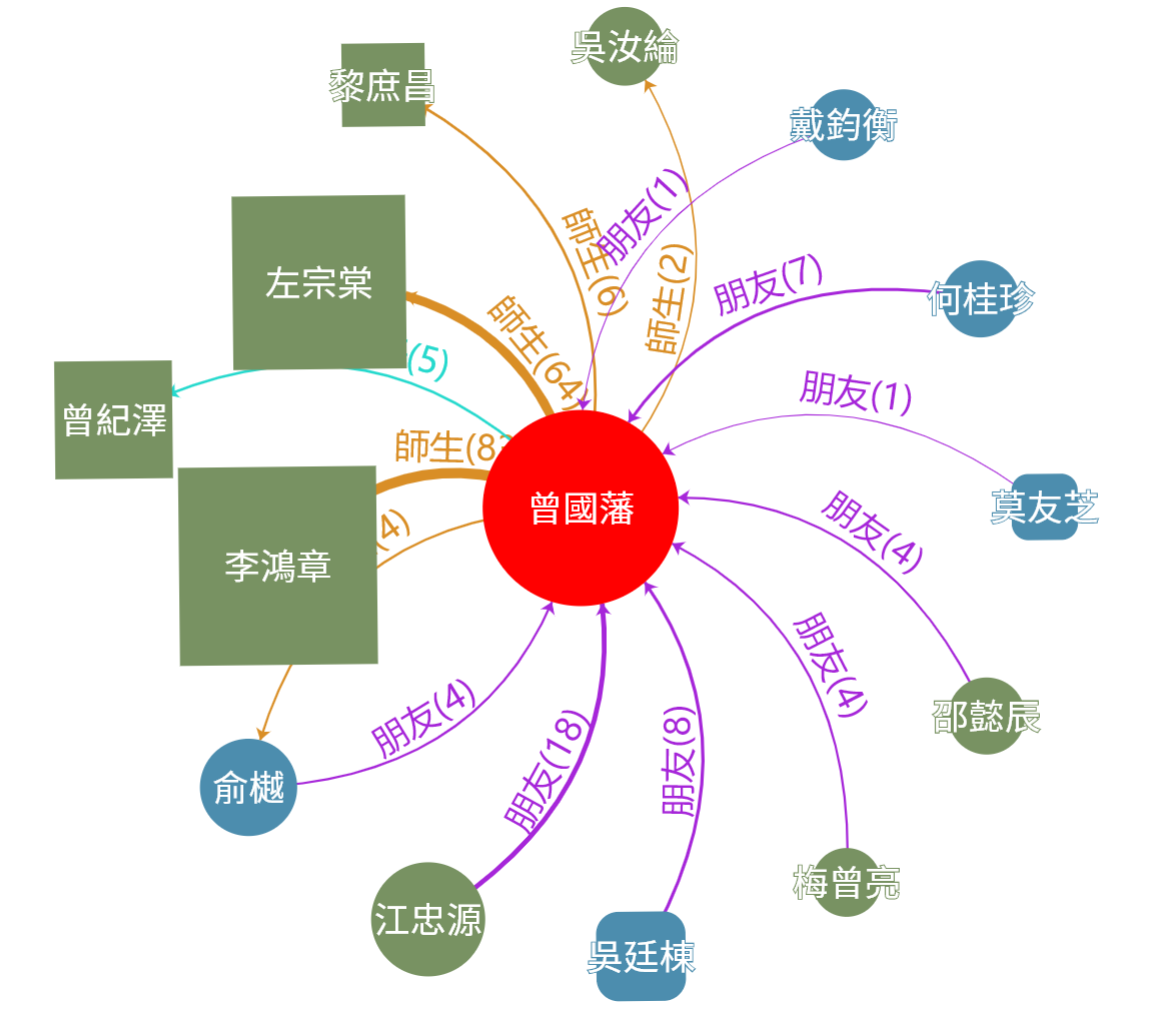
圖 4 力佈局圖
本軟體的輸入資料有兩種,一是關係定義資料,二是以物件的共現資料。而關係定義資料我們以鏈結開放資料的格式來實作,以鏈結資料的主語(subject)、賓語(object)為物件名稱,述語(predicate)為物件之間的關聯,例如圖 4中 「俞樾」的朋友是「曾國藩」,那「俞樾」就是主語、「曾國藩」是賓語、「朋友」是述語。
關係有三種,如表格 1所示。第1種關係定義資料和共現資料都有出現。第2種僅有共現資料但沒有關係定義資料則會呈現黑色並帶有橘色陰影。第3種是有關係定義資料但沒有共現資料,則會呈現虛線。
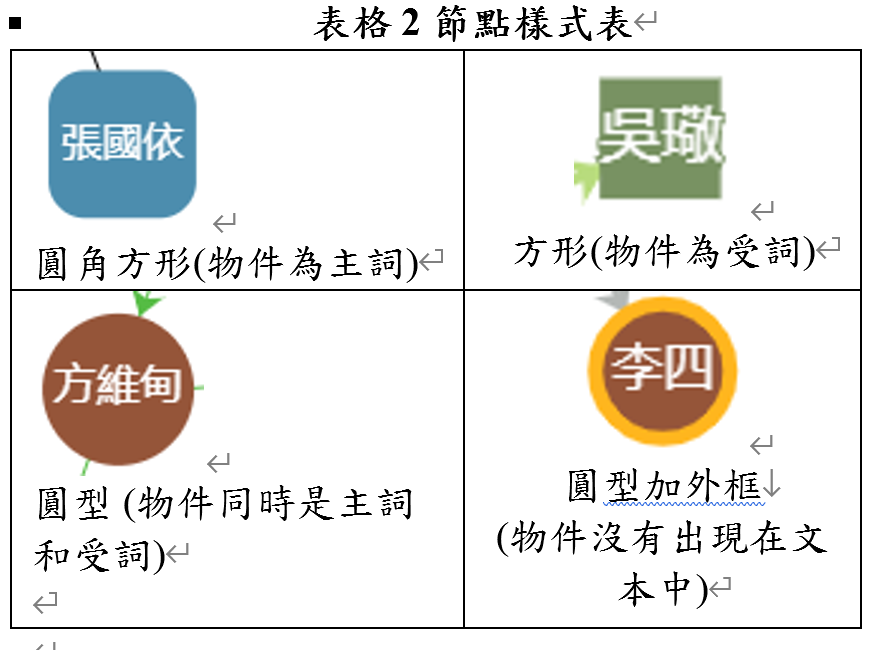
節點的形狀不同也代表著不同的意義如圖 4,節點的樣式如表格 2所示,共有三種:1.如果物件在關係定義資料中為主語就會呈現圓角方形。2.如果物件在關係定義資料中為賓語將會呈現方形。3.在關係定義資料中同時是主語與賓語將會呈現圓形。如果物件沒有出現在文本中,則會加上黃色邊框。這些節點樣式可以使使用者快速辨認出在階層的關係中的位階高低。
圖形調整區
圖形調整可以彈性調整圖表細節,能避免空間不夠造成的重疊與擁擠。項目分成圖形切換、整體大小縮放、點的調整和線的調整,調整項目如下:
圖形切換:可以切換環形圖或力布局圖
整體大小縮放:可以放大縮小整個圖形
點的調整:
- 群聚程度:此參數越小越節點密集
- 背景大小:就是節點的大小
- 字體大小:點的標籤字體大小
線的調整: - 線段長短區間:線段長短與共現次數呈反比,我們可以藉由最大最小值去控制其差距程度。
- 線段粗細:粗細也與共現次數成正比
- 字體大小:線段關係的字體大小
搜尋區
搜尋是本軟體的重要功能,可以讓節點與關係結合布林邏輯的and、or、not搜尋。
節點搜尋中,演算法的部分為了配合距離篩選和加快速度,我先用兩次flooding演算法找出可能的路徑縮小範圍加速路線的搜尋。
而關於關係搜尋,兩個節點之間的關係可能不只有一種。我們將會依照關係替線段分類,可以顯示同時擁有多種關係的節點或是去除某些關係。
在搜尋攔下面會提供畫面上的節點與關係列表,使用者可以點選不需要的節點或關係,如果有可能會篩選掉所有結果的節點和關係將會在該節點或關係旁標示(必要)提示使用者。
篩選區
本軟體除了提供可對整體資料或搜尋結果進行的搜尋,我們提供了四種篩選功能:
- 節點出現次數:可以篩選節點在文本中出現的次數,留下出現頻率較高的節點。
- 共現次數:可以篩選兩節點共同出現於同一段文本的次數,留下出現次數較多的關係。
- 距離:如果有做搜尋,就會出現此項目用來篩選距離,會針對不同的搜尋做出不同的反應,如果是and搜尋就會提供指定長度的關係路徑,如果是一般搜尋則會以搜尋的節點為中心擴展到指定層數的節點。
- 中心性:包含四種中心性,分別為中介中心性、親密中心性、程度中心性、偏中心性,使用時先選擇中心性的演算法,再根據計算出之節點分數進行篩選。
案例說明
想利用清史稿的文本與歷史語言研究所的人名威資料庫(以下簡稱人名權威資料庫)找出「吳三桂」和「李鴻章」之間的關係,並研究是否有清史稿沒有共現的關係。
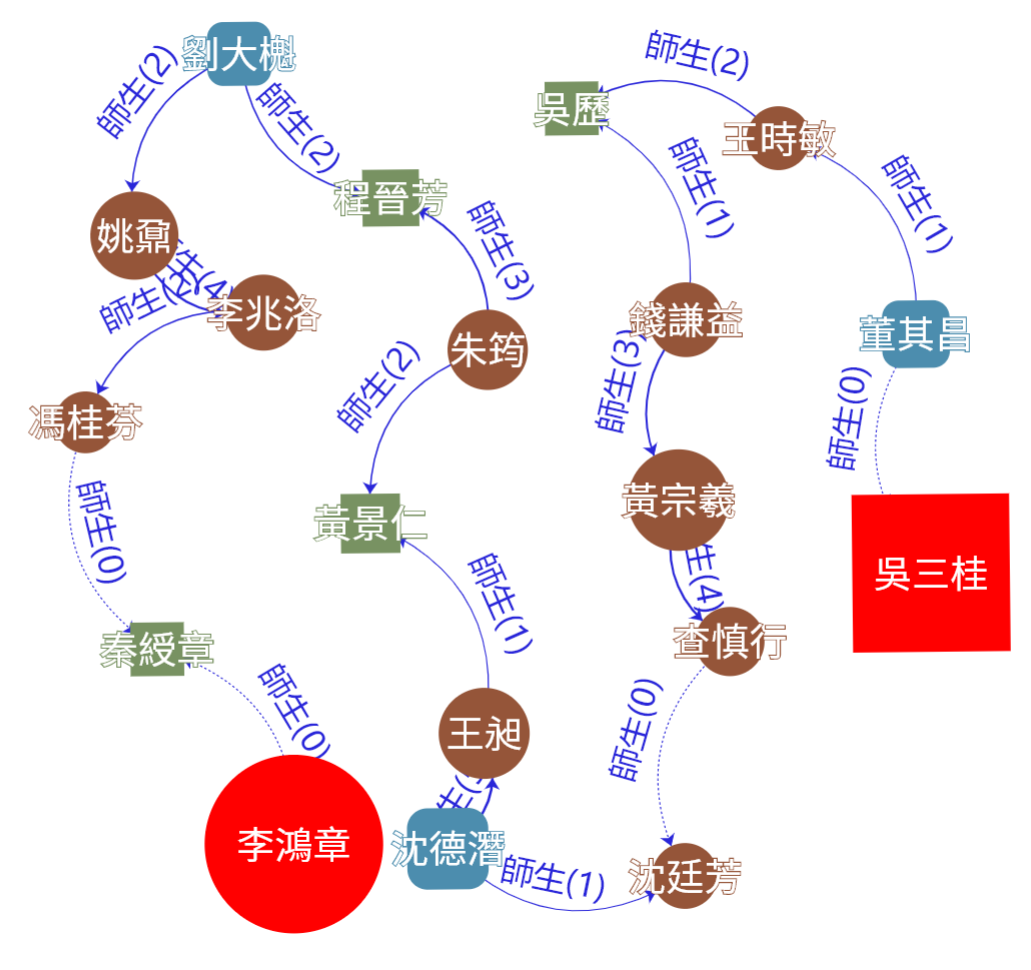
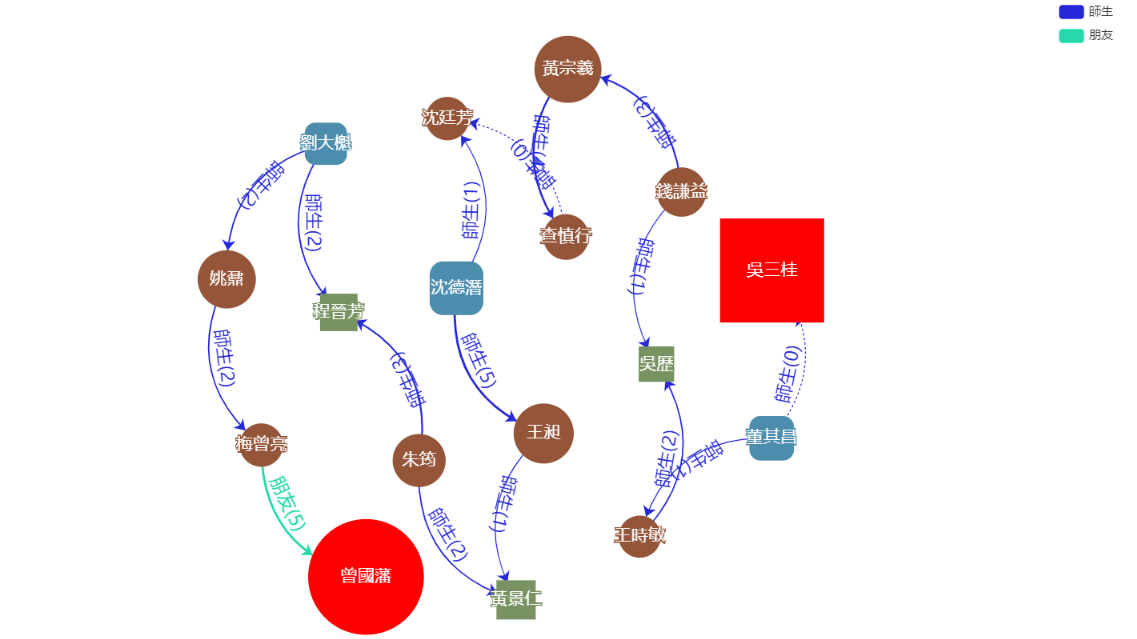
圖 5 吳三桂與李鴻章的關係
- 在清史稿中搜尋「吳三桂」(1612~1678) and 「李鴻章」(1823~1901)就會找出他們兩節點之間的所有關係。
- 接著我們再搜尋and 師生關係就可以透過資料的視覺化可以進一步得到以下發現(如圖 5)。
我們可以從畫面中發現到看似無關聯且年份相差145年的兩人可以藉由多人及師生關係將他們連在一起。其中虛線代表有些關係沒有在清史稿中的人物沒有仔同一文本段落共同出現過,但在人名權威資料庫卻有定義他們的關係,這可以整合清史稿與人名權威資料庫之紀錄,使分析能更加完整。
也可以同時搜索多種條件,如再搜尋 or 「曾國藩」就會給出與「吳三桂」與「李鴻章」的關係和「吳三桂」與「曾國藩」的關係。
未來發展
- 加入使用者定義同意字
- 語意化搜索
- 機器學習分群
- 加入密度、趨勢等社會網路分析工具
- 連結網路上的LOD庫如(如DBpedia、Wikidata)以補充物件的資訊與物件間的關係