Project Details
- 開發者 : 李彥瑾
- 語言&環境 : JAVA/Flask/Python
數位人文平台-文本分詞
功能介紹
CKIP 及 Stanford 分詞的 API 和提升分詞速度。
分詞系統在平台中的應用
數位人文平台在協助數位研究之前,需要做一些自然語言前處理,先將文本分詞過後,使用者就可以對文本做「間距查詢」及「引導查詢」。平台目前使用 CKIP、Jieba、Stanford 三種分詞系統。
測試
撰寫多主機分詞之前,先測試了三個分詞系統的分詞速度,了解三個分詞系統各自的瓶頸。測試結果發現 Jieba 的分詞速度遠遠快於 CKIP 和 Stanford。而 CKIP 設計的原因,每次呼叫 CKIP 分詞都需要重新載入模組,花費的時間最久,於是希望能夠將分詞的動作用多執行緒來實作。
多執行緒實作
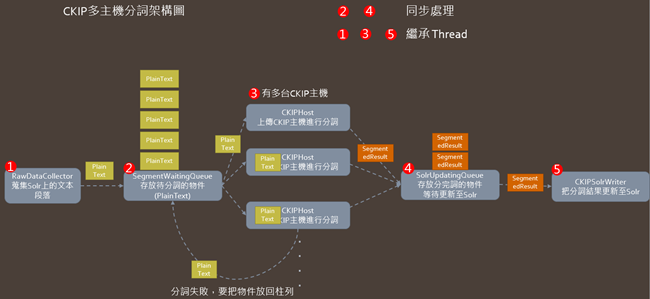
分詞系統的多執行緒依循 Figure 1 的架構來實作。
Figure 1. CKIP 多主機分詞架構圖
成果
實際比較單執行緒和雙執行緒對兩本文本的處理速度的結果如 Figure 2,確實減少了對文本分詞花費的時間。
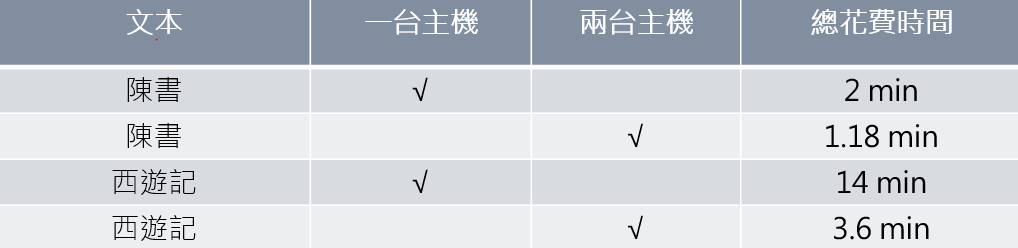
Figure 2. 單執行緒與多執行緒比較