學習使用斷詞系統
實習期間參與到的是與自然語言處理(NLP)有關的專案。因一開始的時候先學習使用三個的斷詞引擎,分別為CKIP、Jieba、Stanford。
CKIP
CKIP是中研院資訊所開發的斷詞引擎,是第一個具備未知詞偵測與句法詞類預測能力的中文分詞系統。在繁體中文斷詞具有主導地位。
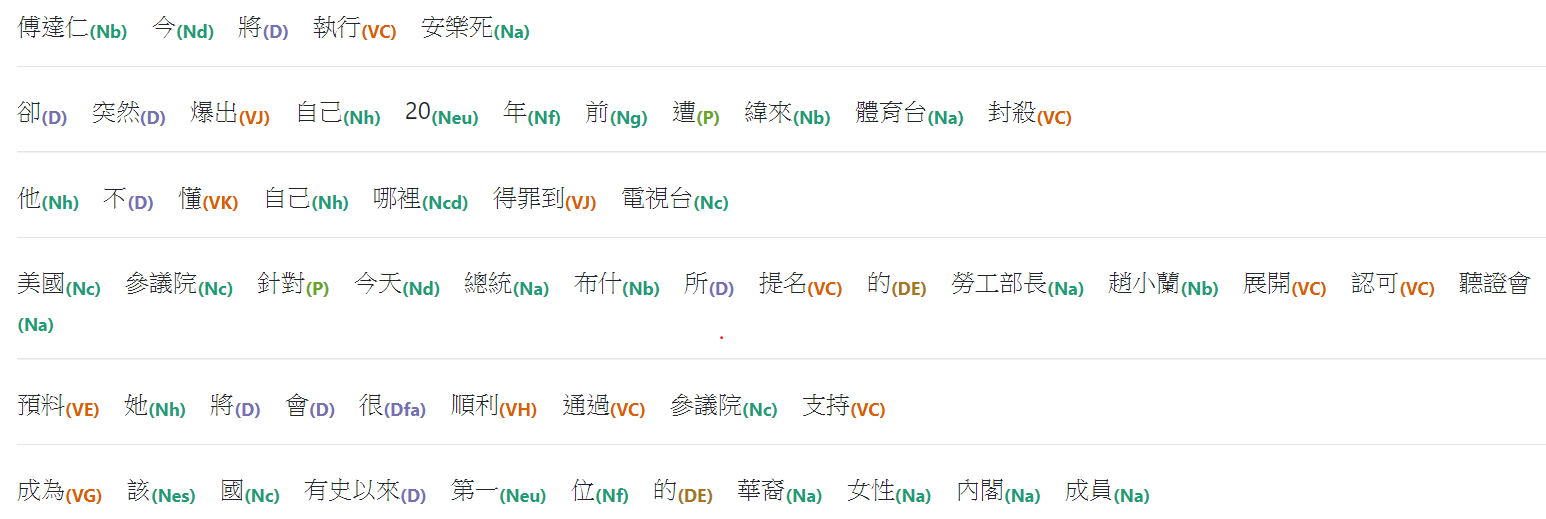
Figure 1. CKIP斷詞結果
CKIP pipline 是一個很豐富的自然語言工具,其功能有斷詞、詞性標註、實體辨識、指代消解、關係抽取、剖析系統(Parsing Tree)等功能。
Jieba
Jieba也是一個開源的斷詞系統,其原始碼可以在GitHub找到。Jieba的優點是速度快,並且替換字典檔容易。不過字典檔對於Jieba就顯得更為重要,如果遇到沒有在字典檔中的詞,斷詞結果就不會有詞性標註。
下圖紅色框框是詞性標註的欄位

Figure 2. Jieba斷詞結果
Stanford
Stanford對於中英文斷詞有各自的套件可以下載。練習的時候是針對英文文本斷詞。英文斷詞相對中文來說較為單純,比較不會有歧異字的問題,所以斷詞的結果也比較精確。
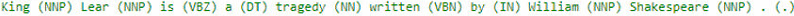
Figure 3. Stanford英文斷詞結果
在暑假期間嘗試了 Stanford 的繁體中文斷詞,Stanford 可以用自己的語料庫訓練斷詞模型,Stanford Core NLP 也提供多國語言的斷詞功能。是一個具有彈性的斷詞工具。下圖是Stanford中文斷詞的結果。

Figure 4. Stanford繁體中文斷詞結果
## 參考資料 1. [https://ckip.iis.sinica.edu.tw/demo/](https://ckip.iis.sinica.edu.tw/demo/) 2. [https://github.com/GlassyWing/better-jieba](https://github.com/GlassyWing/better-jieba) 3. [https://stanfordnlp.github.io/CoreNLP/download.html](https://stanfordnlp.github.io/CoreNLP/download.html)